Individual confidentiality is protected in all U.S. Census Bureau (USCB) data products under current federal law. Recently however, innovations in computational science, combined with widely available sources of public data, are making it easier for outside parties to potentially identify individuals (Garfinkel et al. 2018; Jarmin 2018). It is now more difficult for the Bureau to provide quality statistical information while simultaneously safeguarding individual confidentiality (Abowd 2018). As a result, the Bureau has explored different techniques to uphold data privacy standards.
Beginning with 2020 Census data products, the USCB is implementing differential privacy to protect respondent confidentiality. In most simple terms, differential privacy distorts the data by injecting “noise” into publicly available data, making it more difficult to identify individuals. Differential privacy attempts to strike a balance between privacy and accuracy. However, certain populations require more data distortion to guarantee the same level of privacy compared to larger populations. Communities of color, for example, are one group that will unfortunately shoulder the unequal costs of differential privacy. More noise will render less accurate data, likely leading to “wildly inaccurate numbers” for sub-county geographies (Wezerek and Van Riper 2020).
Knowing the extent to which differential privacy renders data unreliable and the implications for public policy remains largely underexplored. Our concern is that unequal adjustments across population subgroups and space will disproportionately affect the true representation of communities of color, 1) distorting and potentially silencing the stories of already marginalized communities, and 2) making it more difficult to achieve data-driven, equity-focused policy.
The USCB released demonstration data files so data users could assess the potential effects of differential privacy. Our analysis is based on the first vintage demonstration data, released in October 2019. The USCB made adjustments to this vintage, releasing a revised demonstration file in May 2020. However, based on our analysis, the 2020 vintage produced greater data distortion for populations of color at the census tract-level compared to the 2019 vintage.
In this white paper, we address two questions: 1) how reliable are differentially-private data for Arizonans of color? 2) to what extent does differential privacy introduce unequal data distortion among Arizonans of color at sub-county geographies?
Key Findings
How reliable are differentially-private data for Arizonans of color?
- Differential privacy error is severe for non-Hispanic populations of color and negligible for non-Hispanic White and Hispanic/Latino populations in Southern Arizona (Table ES1).
- Differential privacy error renders data for non-Hispanic populations of color unreliable across many census tracts.
- Differential privacy introduces data distortion that could make it difficult, and in some cases improbable, to realize data-driven and equity-focused governance.
- Differential privacy error introduces issues of data injustice because non-Hispanic populations of color are more likely to shoulder the disproportionate costs of differential privacy—more noise rendering less accurate data.
| Median Actual Population | Median Absolute Error | Relative Error | |
|---|---|---|---|
| White | 1,928 | 12 | 0.6% |
| Hispanic/Latino | 1,002 | 27 | 2.7% |
| American Indian and Alaska Native | 30 | 8 | 26.7% |
| Asian | 62 | 10 | 16.1% |
| Black/African American | 76 | 11 | 14.5% |
| Native Hawaiian and Pacific Islander | 3 | 3 | 100.0% |
| Other | 4 | 3 | 75.0% |
| Two or More Races | 58 | 14 | 24.1% |
Table ES1. Median Population and Differential Privacy Error by Race/Ethnicity for Southern Arizona Census Tracts
Note: Racial groups are reported as individuals not identifying as Hispanic/Latino.
Source: Calculated by authors using data from the U.S. Census Bureau (2019b), accessed through Manson et al. (2020).
To what extent does differential privacy introduce unequal data distortion among Arizonans of color and across census tracts?
- Population size and race/ethnicity, not rural-urban status, are statistically significant factors of differential privacy error in Southern Arizona census tracts.
- More than half of all census tracts—55%—in Santa Cruz, Pima, Cochise, and Yuma Counties have at least one racial/ethnic group with severe data distortion.
- Our web-based map application and dashboard, available here, features an Error Index that identifies areas disproportionately affected by differential privacy. This allows users to explore the geography of differential privacy error by race/ethnicity across Southern Arizona census tracts (Figure ES1).
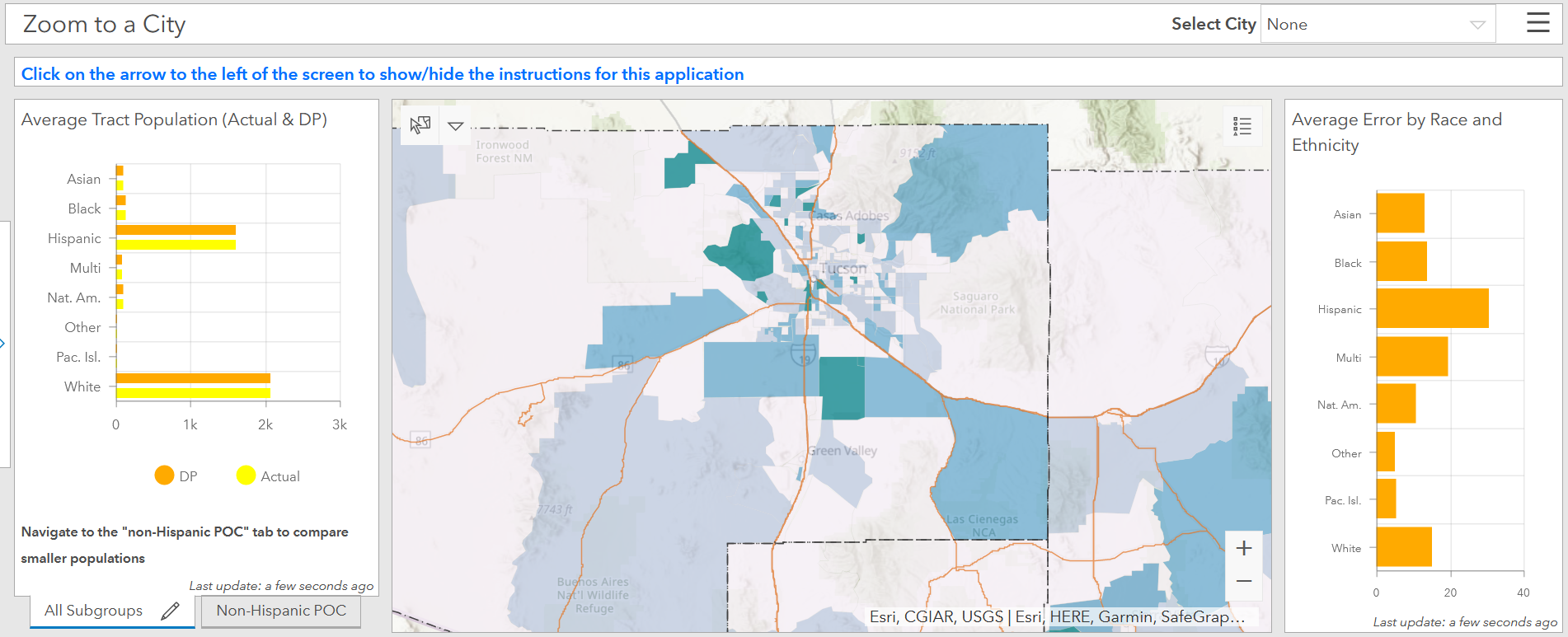
Figure ES1. Southern Arizona Differential Privacy Dashboard
Note: Racial groups are reported as individuals not identifying as Hispanic/Latino.
Source: Map created by authors using data from the U.S. Census Bureau (2019b), accessed through Manson et al. (2020).
On-the-Ground Example
Differential privacy error will significantly affect the accuracy of 2020 Census data, especially for population subgroups, sub-county geographies, and less-populated areas. For example, consider the differential privacy error for the 2010 Black/African American population in Census Tract 25.01, located near the Santa Cruz River Park in South Tucson. The reported Census 2010 population is 243 individuals, compared to a differentially-private value of 381 (Table ES2). This results in an absolute error of 138 individuals and a relative error of 57% (i.e., the relative error is more than half of the actual value). Put another way, the differential privacy error is so large that it masks the actual population decline of 39 Black/African American Tucsonans during 2000 to 2010; instead, differential privacy yields a population increase of 99 people (Table ES2).
Differential privacy error is significant. It will almost certainly limit our ability to understand local neighborhood dynamics, make it more difficult to accurately measure disparate health and economic outcomes, and materially affect the Making Action Possible (MAP) data indicators. Our findings illustrate that less-accurate census data will almost certainly make it more difficult to achieve data-driven, equity-focused policy in Southern Arizona.

Table ES2. 2000 and 2010 (Actual and Differentially-Private) Black/African American Population, Census Tract 25.01
Note: Racial groups are reported as individuals not identifying as Hispanic/Latino.
Source: Calculated by authors using data from the U.S. Census Bureau (2019b), accessed through IPUMS (2019).
In February 2021, the USCB announced plans for the final privacy-loss budget for 2020 Census data products. Unlike the privacy-loss budget used in the demonstration data, the final privacy-loss budget for 2020 Census data will yield less noise and more accurate data. This decision, we believe, is a step in the right direction and is good news for data users. This also means that the data distortion in 2020 census data might be less severe than what we report here. In the end, our high-level findings remain relevant for public policy, research, and governance for two principal reasons: 1) the well-intentioned adjustments of differential privacy disproportionately distort and potentially silence the stories of marginalized communities and, 2) the data distortion could make it difficult, and in some cases improbable, to realize data-driven and equity-focused governance, especially for socially disadvantaged groups and communities of color.






